IA et biodiversité : des données à l’action
Comprendre le vivant, prédire, décider, agir
Introduction
La biodiversité connaît aujourd’hui une dégradation rapide, liée à l’intensification des pressions humaines et au changement climatique. Dans ce contexte, les méthodes classiques d’observation et d’analyse montrent leurs limites, notamment en raison de la complexité des systèmes écologiques et du volume croissant de données à traiter.
L’intelligence artificielle permet de franchir un cap. Elle ne se limite pas à analyser des données, mais permet de les transformer en décisions concrètes. Elle rend possible un passage structuré et opérationnel des données brutes vers l’action environnementale, comme le soulignent de nombreux travaux récents en écologie computationnelle (Reichstein et al., 2019 ; Rolnick et al., 2019).
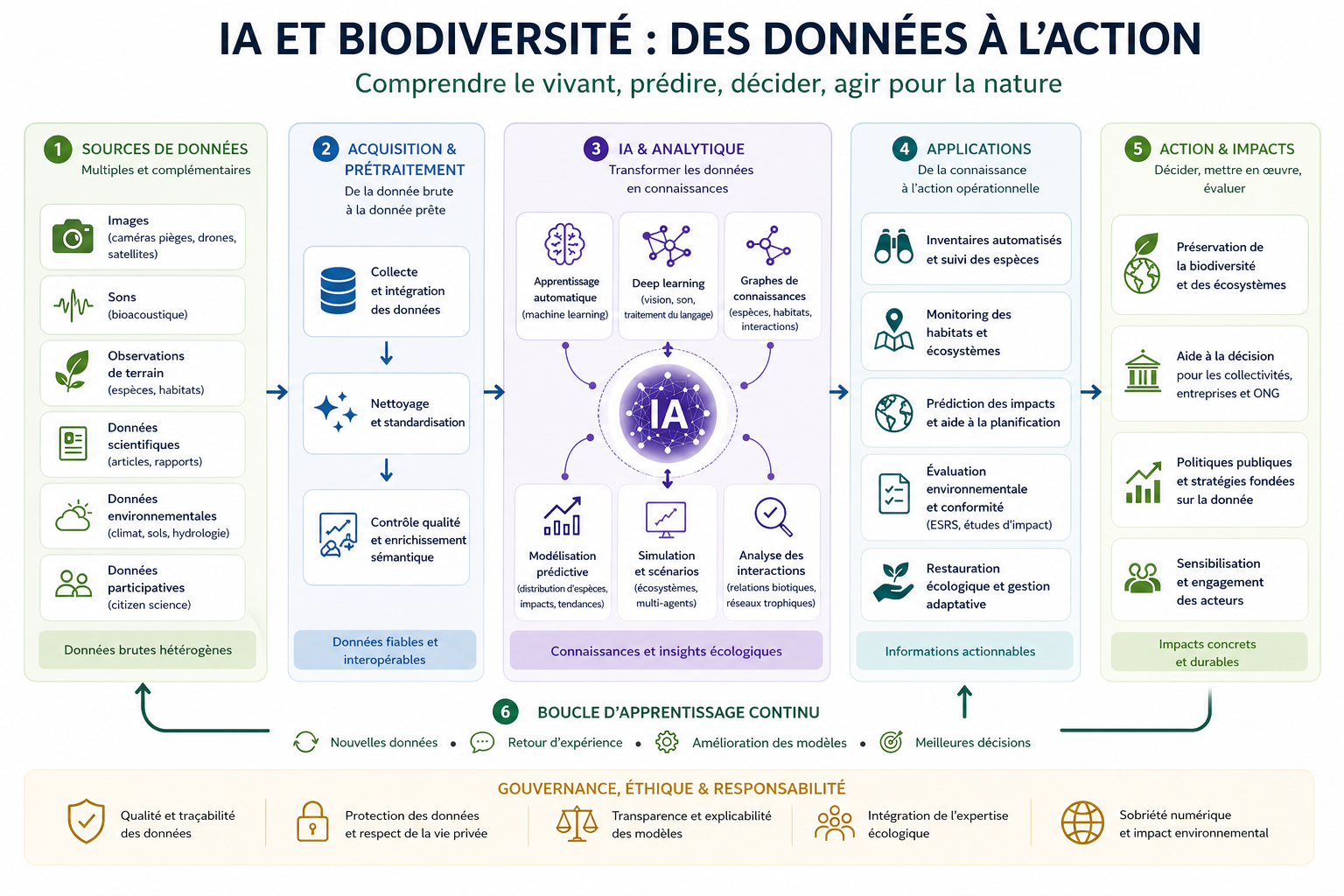
1. Sources de données : une matière première complexe
La compréhension de la biodiversité repose sur une grande diversité de données, issues de sources multiples et souvent hétérogènes. Les images provenant de caméras pièges, de drones ou de satellites permettent d’observer les espèces et les habitats à grande échelle. Les enregistrements sonores issus de la bioacoustique offrent une vision fine de la présence et de l’activité des espèces, notamment dans des environnements difficiles d’accès.
À ces données s’ajoutent les observations de terrain réalisées par les écologues, les bases scientifiques issues de la littérature ou des plateformes ouvertes comme GBIF, ainsi que les données environnementales décrivant le climat, les sols ou l’hydrologie. Enfin, les données participatives issues de la science citoyenne enrichissent considérablement les jeux de données disponibles (Chandler et al., 2017).
L’enjeu principal réside dans le fait que ces données sont souvent fragmentées, bruitées et difficilement comparables entre elles.
2. Acquisition et prétraitement : rendre les données utilisables
Avant toute analyse, il est nécessaire de transformer ces données en un ensemble cohérent et fiable. Cette étape repose d’abord sur la collecte et l’intégration des différentes sources, ce qui implique de gérer des formats variés et d’assurer leur interopérabilité.
Le nettoyage et la standardisation des données sont essentiels pour limiter les biais et améliorer la robustesse des modèles, notamment dans les modèles de distribution d’espèces (Elith & Leathwick, 2009). Cette phase est complétée par un contrôle qualité rigoureux et par un enrichissement sémantique des données.
Ce travail conditionne directement la qualité des analyses produites par l’IA.
3. IA et analytique : transformer les données en connaissances
Une fois les données structurées, l’intelligence artificielle permet d’en extraire de la connaissance. Les méthodes de machine learning ont été largement utilisées pour modéliser la distribution des espèces et les dynamiques écologiques (Olden et al., 2008).
Le deep learning a ensuite permis des avancées majeures, notamment dans la reconnaissance automatique d’espèces à partir d’images issues de pièges photographiques (Norouzzadeh et al., 2018). De même, l’analyse bioacoustique automatisée s’est fortement développée pour le suivi de la faune (Stowell et al., 2019).
Parallèlement, les graphes de connaissance permettent de structurer les relations entre espèces, habitats et interactions biotiques, ouvrant la voie à une représentation systémique des écosystèmes (Poelen et al., 2014 – GloBI).
Ces approches permettent aujourd’hui de produire des modèles prédictifs, des simulations écologiques et des analyses d’interactions complexes.
4. Applications : de la connaissance à l’action opérationnelle
Les applications de l’IA en biodiversité sont désormais nombreuses et opérationnelles. L’automatisation des inventaires naturalistes permet de traiter des volumes massifs de données tout en réduisant les coûts et les biais (Kitzes & Schricker, 2019).
Le monitoring écologique bénéficie également de ces avancées, avec des systèmes capables de détecter en continu les changements dans les écosystèmes. L’IA est aussi utilisée pour prédire les impacts du changement climatique sur la distribution des espèces (Araújo et al., 2019).
Dans un contexte réglementaire, ces technologies contribuent à améliorer la qualité des études d’impact et à produire des indicateurs robustes pour la prise de décision.
Enfin, elles permettent de tester différents scénarios de restauration écologique, en s’appuyant sur des simulations basées sur des modèles complexes.
5. Action et impacts : décider et transformer les territoires
L’objectif final de cette chaîne de transformation est la prise de décision. Les connaissances produites par l’IA permettent de mieux cibler les actions de conservation et d’optimiser les stratégies territoriales.
Les politiques publiques peuvent ainsi s’appuyer sur des données plus précises et actualisées, ce qui améliore leur efficacité. Cette approche s’inscrit dans une logique de gestion adaptative des écosystèmes, fondée sur l’intégration continue de nouvelles informations (Williams et al., 2009).
6. Boucle d’apprentissage continu : un système adaptatif
L’intelligence artificielle permet de mettre en place des systèmes dynamiques, capables d’évoluer en fonction des nouvelles données et des retours d’expérience. Ce fonctionnement en boucle est essentiel pour gérer des systèmes complexes et incertains comme les écosystèmes.
Cette approche rejoint les concepts d’écologie computationnelle et de modélisation adaptative, qui visent à améliorer en continu les modèles à partir des observations (Dietze et al., 2018).
7. Gouvernance, éthique et responsabilité
L’utilisation de l’IA dans le domaine de la biodiversité pose des questions importantes en matière de gouvernance. La qualité des données, la transparence des modèles et l’intégration de l’expertise écologique sont des conditions essentielles pour garantir la pertinence des résultats.
Par ailleurs, plusieurs travaux soulignent la nécessité de développer une IA responsable dans le domaine environnemental, afin d’éviter les biais et les effets contre-productifs (Rolnick et al., 2019).
Conclusion
L’intelligence artificielle constitue aujourd’hui un levier majeur pour la compréhension et la gestion de la biodiversité. Elle permet de structurer des données complexes, de produire des connaissances à grande échelle et de soutenir des décisions plus éclairées.
Cette transformation marque le passage d’une écologie d’observation à une écologie orientée vers l’action. Elle ouvre des perspectives nouvelles, à condition d’être accompagnée d’une rigueur scientifique et d’une gouvernance adaptée.
Références scientifiques
Araújo, M. B. et al. (2019). Standards for distribution models in biodiversity assessments. Science Advances.
Chandler, M. et al. (2017). Contribution of citizen science to biodiversity monitoring. Biological Conservation.
Dietze, M. C. et al. (2018). Iterative near-term ecological forecasting. PNAS.
Elith, J. & Leathwick, J. (2009). Species Distribution Models: Ecological Explanation and Prediction. Annual Review of Ecology.
Kitzes, J. & Schricker, L. (2019). The promise of automated biodiversity surveys. BioScience.
Norouzzadeh, M. S. et al. (2018). Automatically identifying, counting, and describing wild animals in camera-trap images. PNAS.
Olden, J. D. et al. (2008). Machine learning methods in ecology. Journal of Applied Ecology.
Poelen, J. H. et al. (2014). Global Biotic Interactions (GloBI). Ecological Informatics.
Reichstein, M. et al. (2019). Deep learning and process understanding for data-driven Earth system science. Nature.
Rolnick, D. et al. (2019). Tackling Climate Change with Machine Learning. arXiv / CACM.
Stowell, D. et al. (2019). Automatic acoustic detection of birds. Ecological Informatics.
Williams, B. K. et al. (2009). Adaptive management: The U.S. Department of the Interior technical guide.




